槟榔+烟
注: 本文大部分内容来源于flex和bison官方网站文档,如需系统学习直接阅读官方手册更合适
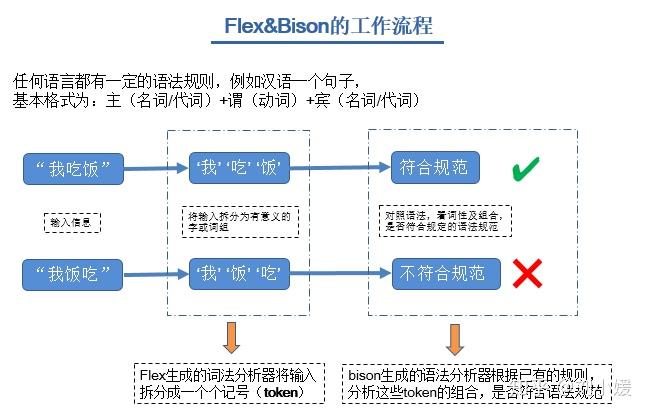
1.槟榔(flex)
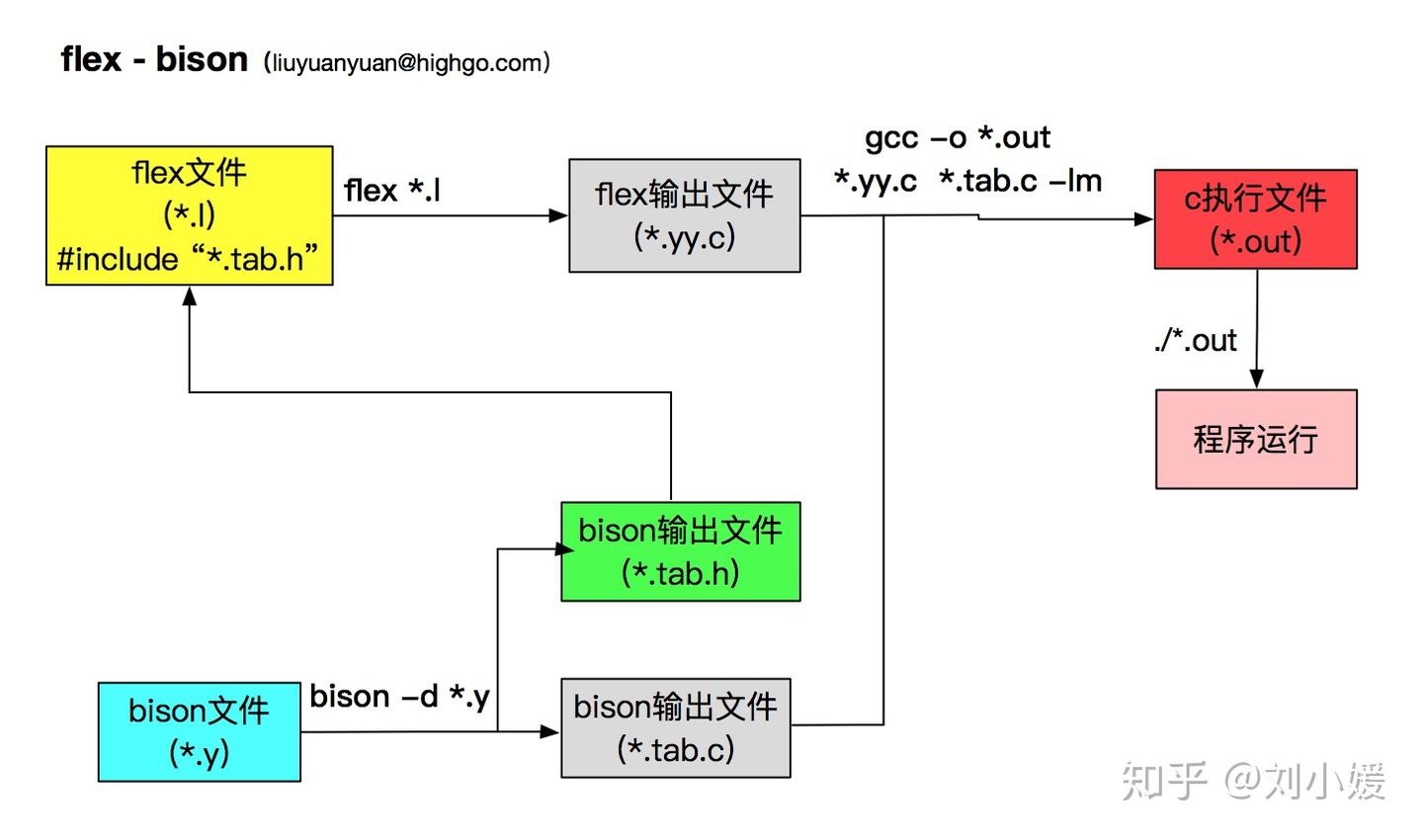
官方手册定义flex为scanner生成工具(scanner指文本的词法分析程序)。flex从后缀.lex文件或标准输入中读取关于词法分析程序的定义(正则表达式,c语言片段)生成scanner的源码(默认lex.yy.c)。scanner的源码可以编译或链接至可执行文件中,运行该可执行文件时,它会分析输入内容中是否出现指定的正则表达式,当找到匹配的表达式时,执行词法分析器中预设的c代码片段。
槟榔的初体验
通过简单的文本字符和行数统计程序,感受槟榔的浓烈辛香。
flex demo.lex编译生成scanner的源,默认lex.yy.c文件- 运行
gcc -g -O0 lex.yy.c编译生成文本词法分析程序a.out - 执行程序
./a.out后,按Ctrl+D结束输入或使用echo 'hello,world\r\n' | ./a.out运行程序
%option noyywrap
%{
int num_lines = 0, num_chars = 0;
%}
%%
\n ++num_lines; ++num_chars;
. ++num_chars;
%%
int main() {
yylex();
printf("# of lines = %d, # of chars = %d\n", num_lines, num_chars);
}
涩口的邀请,麻辣的回响
flex程序分为由%%分割的三部分组成:
1.定义部分
定义部分包含简单名称定义的声明,用于简化scanner规则部分的代码,以及起始条件的声明。名称定义使用name definition的格式,其中,name是一个以字母或下划线开头,后跟零个或多个字母、数字、下划线或短横线的单词。definition是从名称后第一个非空白字符开始,直到行尾的内容。规则定义可以通过{name} 的形式引用,并将展开为(definition)
DIGIT [0-9] // DIGIT定义为匹配单个数字的正则表达式
ID [a-z][a-z0-9]* // ID定义为匹配一个字母后跟零个或多个字母或数字的正则表达式
%top {
/* 此代码会出现在生成文件的顶部。 */
#include <stdint.h>
#include <inttypes.h>
}
%%
/*
* 展开:([0-9])+"."([0-9])* *
*/
{DIGIT}+"."{DIGIT}* // 匹配一个或多个数字,后跟一个.,然后是零个或多个数字
未缩进的注释(即以/*开头的行)会被原样复制到输出中,直到遇到下一个*/。任何缩进的文本或由%{和%}包围的文本也会被原样复制到输出中会移除%{和%}符号)。%{和%} 必须单独占据一行且不能缩进。%top块与%{ … %}块类似,但%top块中的代码会被移动到生成文件的顶部,在任何定义之前。%top块适用于需要定义某些预处理器宏或在生成代码前包含某些文件的情况。允许使用多个%top块,且它们的顺序会被保留。
2.规则定义
规则部分由一系列的pattern action代码组成,其中pattern(模式)不能缩进而action(动作)必须从同一行开始。和定义部分一样,任何缩进文本或被%{和%}包围的文本都会原样复制到输出中,其中%{和%}符号会被移除。%{和%}必须各自单独占一行且无缩进。
%%
// 第一条规则之前的缩进代码
int localVar = 0; // 局部变量,仅在扫描例程中使用
printf("Scanner initialize.\n");
%{
int num_lines = 0, num_chars = 0;
%}
\n ++num_lines; ++num_chars;
username printf("Scanner process.\n");
. ++num_chars;
printf("Scanner complete.\n");
%%
在规则定义部分,任何出现在第一条规则之前的缩进文本或被%{和%}包围的文本,可用于声明扫描例程的局部变量,以及(在声明之后)定义每次扫描例程被调用时需要执行的代码。规则部分中其他缩进文本或%{….%}包围的文本也会被直接复制到输出中,但其含义未明确定义,并且可能会导致编译时错误。规则定义节的内容最终输出在yylex核心函数中,第一条规则前的c代码片段置于匹配前,规则间的c代码生成在switch-case中,规则定义最后的c代码片段是未定义的行为(本例中被忽略,没有输出在lex.yy.c文件中)。
3.用户代码
用户代码部分会被原样复制到生成的lex.yy.c文件中。它通常用于定义与扫描器相关的辅助函数,这些函数可以调用扫描器,也可以被扫描器调用。这个部分是可选的,如果用户代码部分不存在,输入文件中的第二个%%也可以省略。该部分定义的c代码定义于lex.yy.c中,主要在此处编译部分辅助代码。
高阶隐藏副本:
section A: 怎么样是不是很简单?下面开始挂档踩油门,先来一档速度(5~10km/h)
- 条件激活规则(摘自参考文献8)
%option noyywrap noline main
%{
#include <iostream>
%}
%x textSpan str
%%
"$" { BEGIN(textSpan); }
\" { printf("string:"); BEGIN(str); }
<textSpan>\" { BEGIN(INITIAL); printf("textspan:"); BEGIN(str); }
<str>[^"]*\" { BEGIN(INITIAL); printf("%s\n", std::string(yytext, yyleng-1).c_str()); }
%%
上面代码片段,定义了排他性状态textSpan和str(亦可以在两行申明),(%s定义兼容性状态)。规则部分的前两条规则代码,定义如何快速进入两种状态,后两句规则代码描述在对应状态下的后续行为,(规则1)在textSpan状态下,继续输入双引号,会执行{ BEGIN(INITIAL); printf("textspan:"); BEGIN(str); },陷入str状态(textSpan失效),(规则2)在str状态下,继续输入除双引号以外的一个或多个字符会执行规则2申明的action。另外,上面代码包含了iostream头文件,推断flex可以编译出c++类型的源文件代码。
ps: INITIAL状态是内建的默认状态,你不需要显式定义它,用于表示输入流刚开始扫描时的初始状态。
<*>.|\n ECHO;,这条规则可以定义默认行为,英文句话匹配除换行外的任意字符,|表示或逻辑,\n匹配换行,因此该规则可以表述为,在任何状态下,默认执行ECHO这个内建的宏操作。
在下面这个例子中,如果每次调用yylex函数时,enter_special全局变量有效,则进入SPECIAL状态。
int enter_special;
%x SPECIAL
%%
if (enter_special)
BEGIN(SPECIAL);
<SPECIAL> do_something();
... 更多规则 ...
下面的例子摘自jq源码部分,\\[\\\n]|. { }匹配行连续符或任意字符,执行空操作。语句try_exit(yytext[0], YY_START, yyscanner)中的YY_START内置宏,表示扫描器当前状态,yytext存储当前匹配的字符串。
%s IN_PAREN
%s IN_BRACKET
%s IN_BRACE
%s IN_QQINTERP
%x IN_QQSTRING
%x IN_COMMENT
%{
static int enter(int opening, int state, yyscan_t yyscanner);
static int try_exit(int closing, int state, yyscan_t yyscanner);
%}
%%
"#" { yy_push_state(IN_COMMENT, yyscanner); }
<IN_COMMENT>{
\\[\\\n]|. { }
\n { yy_pop_state(yyscanner); }
}
<IN_COMMENT><<EOF>> { yy_pop_state(yyscanner); }
"["|"{"|"(" {
return enter(yytext[0], YY_START, yyscanner);
}
"]"|"}"|")" {
return try_exit(yytext[0], YY_START, yyscanner);
}
"\"" {
yy_push_state(IN_QQSTRING, yyscanner);
return QQSTRING_START;
}
<IN_QQSTRING>{
"\\(" {
return enter(QQSTRING_INTERP_START, YY_START, yyscanner);
}
"\"" {
yy_pop_state(yyscanner);
return QQSTRING_END;
}
(\\[^u(]|\\u[a-zA-Z0-9]{0,4})+ {
/* pass escapes to the json parser */
jv escapes = jv_string_fmt("\"%.*s\"", (int)yyleng, yytext);
yylval->literal = jv_parse_sized(jv_string_value(escapes), jv_string_length_bytes(jv_copy(escapes)));
jv_free(escapes);
return QQSTRING_TEXT;
}
[^\\\"]+ {
yylval->literal = jv_string_sized(yytext, yyleng);
return QQSTRING_TEXT;
}
. {
return INVALID_CHARACTER;
}
}
%%
static int try_exit(int c, int state, yyscan_t yyscanner) {
char match = 0;
int ret;
switch (state) {
case IN_PAREN: match = ret = ')'; break;
case IN_BRACKET: match = ret = ']'; break;
case IN_BRACE: match = ret = '}'; break;
case IN_QQINTERP:
match = ')';
ret = QQSTRING_INTERP_END;
break;
default:
// may not be the best error to give
return INVALID_CHARACTER;
}
assert(match);
if (match == c) {
yy_pop_state(yyscanner);
return ret;
} else {
// FIXME: should we pop? Give a better error at least
return INVALID_CHARACTER;
}
}
static int enter(int c, int currstate, yyscan_t yyscanner) {
int state = 0;
switch (c) {
case '(': state = IN_PAREN; break;
case '[': state = IN_BRACKET; break;
case '{': state = IN_BRACE; break;
case QQSTRING_INTERP_START: state = IN_QQINTERP; break;
}
assert(state);
yy_push_state(state, yyscanner);
return c;
}
2.action中的特殊指令
- REJECT,允许Flex回退到先前的规则,尝试其他可能的匹配方式。它会选用"第二好的规则",这意味着,它会选择一个匹配当前输入的其他规则(可能是更长的规则,也可能是更短的规则)。
- yymore,保留当前已经匹配的部分,并继续扫描剩余部分。yyless的作用和yymore相反
- input和unput,分别冲输入中读取下一个字符和放回字符,见样例3和4
样例1在输入abc的情况下,程序首先匹配abc执行打印action,reject使得flex回退,输入并未消耗,abc匹配ab,打印ab字符,剩余字符c被最后一条规则消耗。 样例2在输入mega-kludge的情况下,匹配到mega-后,保留已匹配的部分,继续扫描发现匹配kludge,最终输出mega-mega-kludge
%option noyywrap
%%
a { printf("Found 'a'\n"); }
ab { printf("Found 'ab'\n"); }
abc { printf("Found 'abc'\n"); REJECT; }
.|\n { /* eat up any unmatched character */ }
%%
%%
mega- ECHO; yymore();
kludge ECHO;
%%
%%
"ab" {
char c = input(); // 读取一个字符
printf("Got character: %c\n", c);
}
.|\n { ECHO; }
%%
%%
"ab" {
unput('b'); // 将 'b' 重新放回输入流
printf("Character 'b' is pushed back\n");
}
"ba" { printf("Matched 'ba'\n"); }
.|\n { ECHO; }
%%
section B: 还不过瘾,加点油,搞个三档兜兜风(40km/h)
通过%option reentrant或-R参数,可以生成可重入的C扫描器,这样生成的scanner既是可移植的,又是安全的,可以在一个或多个独立的控制线程中使用,不需要与其他线程进行同步。即便在单线程环境,可能也存在实例化多个scanner的场景,比如循环对比不同的输入文件。
官方文档规定可重入的scanner必须满足以下条件:
- %option reentrant必须设置
- 所有的函数增加一个额外的参数,yyscanner
- 在调用yylex之前必须使用yylex_init|yylex_init_extra初始化,结束时使用yylex_destroy销毁
- 用户相关的数据存储与yyextra结构中,在规则部分可以使用宏yyextra访问
- get/set函数,提供对常见flex变量的访问,例如使用,yyget_text函数访问yytext
- 使用等价宏替代所有的全局变量,(例: 在可重入模式下,yytext不再是全局变量,而是宏
#define yytext (((struct yyguts_t*)yyscanner)->yytext_r)
/* This scanner prints "//" comments. */
%option reentrant stack noyywrap
%x COMMENT
%%
"//" yy_push_state(COMMENT, yyscanner);
.|\n
<COMMENT>\n yy_pop_state(yyscanner);
<COMMENT>[^\n]+ fprintf(yyout, "%s\n", yytext);
%%
int main(int argc, char * argv[]){
yyscan_t scanner;
yylex_init (&scanner);
yylex (scanner);
yylex_destroy (scanner);
return 0;
}
section C: 能让我感受D-Cup的胸吗!(方兴,说车速60km/h,把手伸出窗外能感受D-Cup的胸)
- 管理scanner的内存
flex内部使用yyalloc、yyrealloc、yyfree申请和释放内存,这些函数其实是对标准c的简单封装。使用%option noyyalloc noyyrealloc noyyfree,允许开发者重载这些函数。
void* yyalloc(size_t sz, void* extra) {
return jv_mem_alloc(sz);
}
void* yyrealloc(void* p, size_t sz, void* extra) {
return jv_mem_realloc(p, sz);
}
void yyfree(void* p, void* extra) {
jv_mem_free(p);
}
- 常用的辅助宏
- YY_USER_ACTION,在匹配规则的动作执行之前始终运行,发生在匹配前,无论是否匹配到后续规则
- YY_USER_INIT,在首次扫描之前(以及扫描器的内部初始化之前)始终执行
- yy_set_bol,控制当前缓冲区的扫描上下文是否应作为一行的起始位置,进行下一次匹配(参数零,使^规则失效)
- YY_AT_BOL,如果从当前缓冲区扫描的下一个token将启用"^“规则,则宏YY_AT_BOL()返回true,否则返回false
\n yy_set_bol(1);
技巧: 在生成的lex.yy.c中,可以直接使用#line 规则行号+1搜索对应的c实现代码,比如你可能疑惑规则2的action如何定义在yylex函数中,你只需知道规则2在.lex文件中的行号
杀虫消积、生津润肺和利水抗疟
槟榔的起源我并不知道,但FLex(the Fast Lexical Analyzer Generator)是由在Lesk和当时尚在AT&T实习的Eric Schmidt75年共同完成的词法分析器生成程序Lex的改进版本(效率&bug)。槟榔杀虫消积、生津润肺、利水抗疟,而FLex广泛应用于编译器和解释器开发、配置文件解析器、文本处理工具、日志分析与数据挖掘、自然语言处理、数据清洗与格式转换等场景。注意:Lex的主要贡献者Eric Schmidt,曾是google的CEO。加油,陈卓你也可以的!
注: 其实想要摸底那些软件或者库实现依赖flex很简单,apt-cache rdepends flex libfl-dev列出运行时使用flex,apt-cache showsrc libpcap输出的Build-Depends字段显示源码依赖,即编译依赖。
- 在gcc编译器的前端中Flex将输入文件解析成词素token,作为Bison的输入生成抽象语法树。

- clang+llvm,clang作为编译器前端其中也包含词法语法分析功能。
- 请点击移步至,jq工具的scanner定义
- 在tcpdump如何使用FLex,有时间深入分析
2.烟(bison)
bison的前身yacc,是由贝尔实验室的S.C.Johnson基于Knuth大神的LR语法分析理论,于1975~1978年写成。大约1985年,UC Berkeley的研究生Bob Corbett使用改进的内部算法实现了伯克利yacc,来自FSF的Richard Stallman改写了伯克利yacc并将其用于GNU项目,添加了很多特性,形成了今天的GNU Bison。bison现在作为FSF的项目被维护,基于GNU公共许可证发布,Bison是兼容yacc的免费语法生成器。
前置:
- 上下文无关语言,https://pandolia.net/tinyc/ch9_context_free_grammar.html4
- LL(1)分析方法,https://pandolia.net/tinyc/ch10_top_down_parse.html
- bison使用的LR分析方法,https://pandolia.net/tinyc/ch11_buttom_up_parse_a.html
确切的说,bison是一个通用的解析器(相较于flex生成scanner,bison生成的是parser)生成器,通过读取文法文件中使用BNF(一种用来描述cfg的语言或称做语言)描述的上文无关文法,生成对应的解析器代码(带有约束的自下而上的解析器-LALR(1),或另外一种解析器GLR)。一旦熟练掌握Bison,就可以用它开发各种语言解析器,从简单的桌面计算器到复杂的编程语言。
注: Bison生成的解析器允许用于非自由程序。从Bison2.2版开始,这种额外的许可适用于Bison生成的所有解析器,更早的版本(1.24 之前)中,Bison生成的解析器只能用于自由软件中。
烟的第一次告白
虽然bison文件使用.y作为后缀名,但从文本结构形式上讲bison与flex相同,都是以%%分割的,定义部分、规则定义和用户代码三部分组成。
%{
#include <stdio.h>
#include <stdlib.h>
%}
%token NUM
%%
input:
| input line
;
line:
'\n' { printf("Result: %d\n", yylval); }
| expr '\n' { printf("Result: %d\n", yylval); }
;
expr:
NUM { yylval = atoi(yytext); }
| expr '+' NUM { yylval += atoi(yytext); }
| expr '-' NUM { yylval -= atoi(yytext); }
;
%%
int main() {
yyparse();
return 0;
}
bison工具读取指定的文法文件,默认生成以文法文件+.tab.c命名的解析器代码文件。
标题待定
非终止符在Bison的形式文法中类似c语言中的标识符。使用小写字符声明。终止符在Bison中又称为token,使用大写字符书写。
- %code指示符,通过显式的限定符%code字段来标识代码块,确定Bison应该在何处生成这些代码块
- %token,bison会将其转换为解析器中的定义,以便函数yylex可以使用name来代表此token类型的代码(终结符)
高阶隐藏副本:
1.调试
bison命令的–debug|-t|%define parse.trace选项,在生成的parser文件中增加全局变量yydebug的定义并开启YYDEBUG宏,当yydebug为1是开启调试
2.状态转移图
bison的graph参数指定生成的状态转移dot文件,使用dot命令生成转移图(复杂情况不适用)
3.槟榔加烟,法力无边
槟榔加烟,法力无边,抽烟喝酒,永垂不朽。
唉,明知山有虎,偏向虎山行