
算法学习-决策树算法
0.前置知识
样本特征
特征在机器学习、数据分析和模式识别等领域中扮演着至关重要的角色。它们是从数据中提取出来的、能够描述或区分数据样本的属性或度量。特征的类型可以根据不同的分类标准进行划分。
---
config:
layout: default
look: handDrawn
theme: neutral
---
%%{init: {"themeVariables": {"fontSize": "32px"}}}%%
graph TD
样本特征 --> 数值特征
样本特征 --> 图像特征["图像特征<br>如像素值、边缘、纹理、形状等,可以通过图像处理技术提取"]
样本特征 --> 类别特征
样本特征 --> 时间特征["时间特征<br>如日期、时间戳等"]
样本特征 --> 空间特征["空间特征<br>描述物体在空间中的位置、形状、大小等属性的特征,常见于地理信息系统和计算机视觉中"]
样本特征 --> ..............
数值特征 --> |取值范围可以是任意实数|连续型["连续型<br>如身高、体重、温度等"]
数值特征 --> |取值是有限或可数集合|离散型["离散型<br>如年龄(按年计)、人数等"]
类别特征 --> 无序["无序<br>颜色(红、绿、蓝)、国家"]
类别特征 --> 有序["有序<br>考试评级(A、B、C、D)"]
机器学习中,决策树是一个预测模型。决策树描述对象属性(特征)与对象之间的映射关系。对未知数据的预测问题,可以简单由一系列树的遍历操作完成。决策树每个叶子节点都代表一类预测对象,关于对象属性判断的单元组成树的中间节点。决策树具有计算复杂度低,输出结果易于理解,对中间数据缺失不敏感,但容易过拟合等特点。
1.决策树原理
如何构建决策树模型首先需要回答三个问题:
- 样本数据的那些特征维度参与模型的决策
- 这些参与决策的特征的先后顺序如何确定
- 特征的分割点的选取问题,灰分指标超过多少2.5?,应当分类至类别1,否则分类至类别2
分支创建的伪代码:
检测数据集合中的每一个数据是否都属于同一个分类:
if yes so return 分类标签
else
寻找划分当前数据集合的最优特征
划分数据集
创建分支节点
for 每一个划分的子集
调用分支创建的伪代码,并增加返回结果到分支节点中
return 分支节点
1.1基于信息熵的决策树算法
id3算法,C4.5算法(id3算法的改进版)
信息熵
在热力学系统中,熵用来衡量孤立系统的无序程度或混乱程度。同样在决策树中引入熵的概念,衡量样本的不确定性,即某个节点中各个样本分别属于不同类别的混乱程度。数学定义如下:
$$ S = -\sum_{i=1}^{m} p_i \log_2 p_i $$
- $p_i$类别: $i$在集合$S$中的比例
- 熵越高,表示数据越杂乱
决策树算法的机器学习过程,本质上就是“用特征划分训练集,不断降低信息熵”的过程。
信息增益
- 特征划分
在计算信息增益之前,需要先确定每个特征的划分方式,因为信息增益依赖于特征划分后的类别分布才能计算。通常不同特征类型采用不同的划分方式,例如下面饮用酒数据集中的酒精精度特征(连续数值特征),常见的做法是分箱binning处理或阈值搜索来确定划分点。
常见的特征划分算法如下图所示:
---
config:
layout: default
look: handDrawn
theme: neutral
---
%%{init: {"themeVariables": {"fontSize": "32px"}}}%%
graph TD
A[特征划分方案] --> B[分箱算法 Binning]
A --> C[阈值搜索 Threshold Search]
B --> D[无监督分箱]
B --> E[有监督分箱]
D --> D1[等宽分箱 Equal Width]
D --> D2[等频分箱 Equal Frequency]
D --> D3[聚类分箱 K-Means]
E --> E1[基于熵的分箱 MDLPC/决策树]
E --> E2[卡方分箱 ChiMerge]
E --> E3[IV/WOE分箱 金融风控常用]
C --> C1[二分法/贪心搜索]
这里介绍一下,基于熵的分箱MDLPC/决策树算法,步骤如下:
-
步骤1,初始状态,将所有样本看作一个区间
-
步骤2,寻找最优切分点$T$:
遍历该特征下所有相邻两点的平均值作为候选点
计算每个候选点$T$划分后的类别信息熵,找到使$Entropy(A, T; D)$最小的那个点$T^*$$$Entropy(A, T; D) = \frac{|D_{left}|}{|D|} Entropy(D_{left}) + \frac{|D_{right}|}{|D|} Entropy(D_{right})$$
-
步骤3,判定停止MDLP准则,这是该算法的精华。它不仅看熵是否减小,还会计算一个“代价”。只有当信息增益大于某个阈值时,才允许切分。
注意: MDLP并不是只切一次,而是递归进行。每次找到一个最优切分点,如果满足MDLP准则,就继续对左右子区间重复该过程,最终形成多个区间划分(可以得到多个划分点)。
- 特征选择
在决策树的构建过程中,当需要选择某个特征来划分当前剩余样本时,可以使用信息增益作为评价指标。信息增益衡量了选择某个特征后,数据集的不确定性减少的程度。数学上,对于特征$A$的信息增益定义如下:
$$ Gain(S, A) = Entropy(S) - \sum_{v \in Values(A)} \frac{|S_v|}{|S|} Entropy(S_v) $$
- $S_v$,表示特征$A$取值$v$的子集
- 选择信息增益最大的特征作为节点
在实际构建决策树时,通常选择信息增益最大的特征作为当前节点的划分依据,以最大程度降低数据的不确定性。可以理解为,类似于梯度下降法中选择“最大下降方向”,信息增益最大的特征对当前决策最有利,有助于加快学习过程和提升分类效果。
递归构建决策树
- 如果子集纯度为1(熵=0) → 叶子节点,标记类别
- 否则继续对剩余特征计算信息增益
- 遇到特征用完 → 用多数类别作为叶子
以上是id3算法(Iterative Dichotomiser 3)的核心思想,每次迭代都是对信息增益的局部最优求解。id3算法本质是关于信息增益的贪心算法。
1.2基于基尼指数的决策树算法
CART算法
基尼指数
在一个决策树节点中,假设有$K$个类别,第i类样本比例为$p_i$(即该类样本数/节点总样本数),基尼指数或称作Gini impurity定义为:
$$ Gini = 1 - \sum_{i=1}^{K} p_i^2 $$
可以理解为,从节点中随机抽两个样本,它们属于不同类别的概率。
基尼增益
假设使用特性$X$作为划分特征,$s$是特征的划分点,则划分后的加权基尼,数学表述如下:
$$ Gini_{\text{split}}(X, s) = \frac{N_L}{N} Gini(D_L) + \frac{N_R}{N} Gini(D_R) $$
与信息增益相似,实际是在待分类样本中,求解使得加权基尼最小时的,特征$X$及其划分点$s$,数学表示:
$$ (\hat{X}, \hat{s}) = \arg \min_{X, s} \text{Gini}_{\text{split}}(X, s) $$
递归构建决策树
决策树的构建过程也与id3算法类似,这里不再赘述。
1.3基于卡方检验CHAID算法
CART,改进版本QUEST,统计派的决策树算法代表
$$\chi^2 = \sum \frac{(O - E)^2}{E}$$
其中:
- $O$ (Observed):观察值
- $E$ (Expected):理论值
算法核心:
- 将特征的取值(连续特征先分箱)作为分组;
- 对特征的每两个分组之间在目标变量上的分布进行卡方检验;
- 若两组差异不显著,则合并这些组;
- 最终,保留差异显著的分组作为决策树的分裂节点;
- 对差异不显著或已合并的组,暂不在当前节点分裂。
基于卡方检验CHAID算法核心是在回答,选择当前特征作为分类标准是否对结果产生显著影响。
2.实验数据集
使用sklearn.datasets中的饮用酒数据集学习决策树算法,该数据集包含178个样本数据, 数据包含13个特征维度,数据被分类至3个类别。这里使用80%的样本作为训练集,剩余样本作为验证集,评价模型效果。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
from IPython.display import display
wine_样本特征_zh = [
"酒精精度", "苹果酸", "灰分", "灰分碱度", "镁",
"总酚", "类黄酮", "非类黄酮酚类", "原花青素", "色泽强度",
"色调", "稀释液光密度比值", "脯氨酸"
]
def show_wines_data(x,y):
display(
pd.concat(
[pd.DataFrame(x, columns=wine_样本特征_zh), pd.DataFrame(y, columns=["类别"])],
axis=1
)
)
def main():
wines = load_wine()
X_train, X_test, Y_train, Y_test = train_test_split(wines.data, wines.target, test_size=0.2, random_state=42)
show_wines_data(X_train, Y_train)
if __name__ == "__main__":
plt.rcParams["axes.unicode_minus"] = False
main()
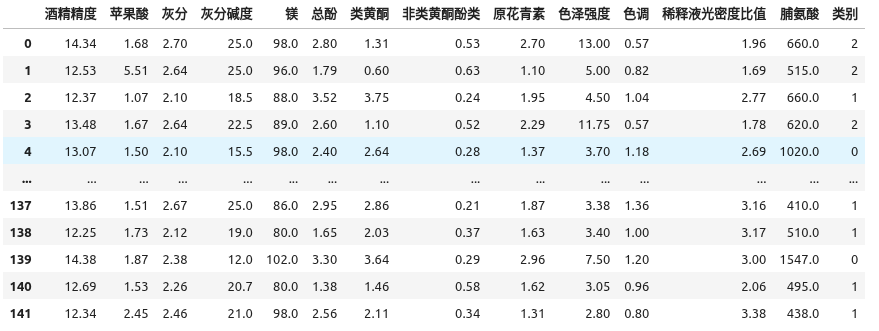
3.模型训练
# pylint: disable=no-member
# pylint: disable=missing-module-docstring
# pylint: disable=consider-using-f-string
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree, export_graphviz
import pandas as pd
from IPython.display import display
import graphviz
wine_样本特征_zh = [
"酒精精度",
"苹果酸",
"灰分",
"灰分碱度",
"镁",
"总酚",
"类黄酮",
"非类黄酮酚类",
"原花青素",
"色泽强度",
"色调",
"稀释液光密度比值",
"脯氨酸",
]
def show_wines_data(x, y):
"""
显示葡萄酒数据
"""
display(
pd.concat(
[
pd.DataFrame(x, columns=wine_样本特征_zh),
pd.DataFrame(y, columns=["类别"]),
],
axis=1,
)
)
def main():
"""
入口函数
"""
wines = load_wine()
x_train, x_test, y_train, y_test = train_test_split(
wines.data, wines.target, test_size=0.2, random_state=42
)
clf = DecisionTreeClassifier(criterion="entropy")
clf.fit(x_train, y_train)
# sklearn统一约定:
# 所有学习到的参数、模型系数、特征重要性等都会带_,只有在调用fit函数后才会被赋值
print("训练集准确率: {:.2f}%".format(clf.score(x_train, y_train) * 100))
print("测试集准确率: {:.2f}%".format(clf.score(x_test, y_test) * 100))
print("特征重要性: ", clf.feature_importances_)
dots = export_graphviz(
clf,
out_file=None,
feature_names=wine_样本特征_zh,
class_names=wines.target_names,
filled=True,
rounded=True,
)
graph = graphviz.Source(dots)
display(graph)
if __name__ == "__main__":
plt.rcParams["axes.unicode_minus"] = False
main()
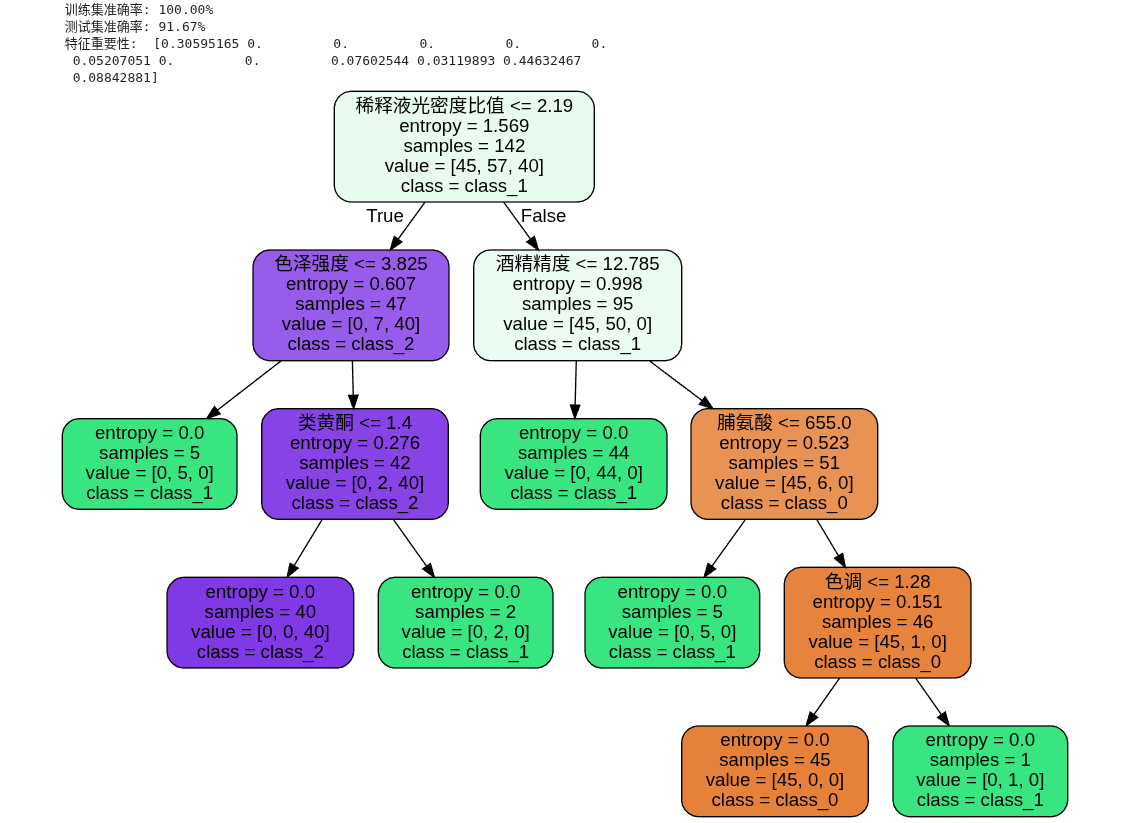
4. 扩展进阶
使用onnx项目提供的python库sklearn-onnx,将生成的决策树模型导出成模型文件
def export_ds2onnx_model(clf, x_test):
"""导出决策树模型为ONNX格式
Args:
clf (DecisionTreeClassifier): 训练好的决策树模型
x_test (ndarray): 测试数据
tips:
1. initial_type: 定义输入数据的类型和形状, ONNX模型需要知道输入数据的格式才能正确地进行推理。
2. options: 这里设置了zipmap为False, 表示在转换过程中不使用zipmap操作, 这样输出的ONNX模型将直接输出类别标签而不是概率分布。
"""
initial_type = [("float_input", FloatTensorType([None, x_test.shape[1]]))]
options = {id(clf): {"zipmap": False}}
onx = convert_sklearn(clf, initial_types=initial_type, options=options)
with open("ds-wines.onnx", "wb") as f:
f.write(onx.SerializeToString())
使用onnxruntime提供的c语言的api,加载并运行该模型,对样本数据进行预测
#include <assert.h>
#include <stdbool.h>
#include <stdio.h>
#include "onnxruntime_c_api.h"
#define ORT_MODEL_PATH "../scripts/ds-wines.onnx"
typedef struct ort_ctx {
const OrtApi *api;
OrtEnv *env;
OrtSession *session;
OrtAllocator *allocator;
OrtMemoryInfo *memory;
const char *model_path;
} ort_ctx_t;
typedef enum ort_ctx_action {
DO_INIT,
RELEASE,
} ort_ctx_action_t;
#define SAFE_RELEASE_VAL(ctx, val) \
do { \
if (val) ctx.api->ReleaseValue(val); \
val = NULL; \
} while (0)
OrtStatus *ort_env_helper(ort_ctx_t *ctx, ort_ctx_action_t action) {
if (action == DO_INIT)
return ctx->api->CreateEnv(ORT_LOGGING_LEVEL_WARNING, "test", &ctx->env);
if (ctx->env) {
ctx->api->ReleaseEnv(ctx->env);
ctx->env = NULL;
}
}
OrtStatus *ort_ses_helper(ort_ctx_t *ctx, ort_ctx_action_t action) {
if (action == DO_INIT)
return ctx->api->CreateSession(ctx->env, ctx->model_path, NULL,
&ctx->session);
if (ctx->session) {
ctx->api->ReleaseSession(ctx->session);
ctx->session = NULL;
}
}
OrtStatus *ort_act_helper(ort_ctx_t *ctx, ort_ctx_action_t action) {
if (action == DO_INIT)
return ctx->api->GetAllocatorWithDefaultOptions(&ctx->allocator);
// 默认全局allocator,不应该被释放
// 参见api的说明文档
if (ctx->allocator) ctx->allocator = NULL;
}
OrtStatus *ort_mem_helper(ort_ctx_t *ctx, ort_ctx_action_t action) {
if (action == DO_INIT)
return ctx->api->CreateCpuMemoryInfo(OrtArenaAllocator, OrtMemTypeDefault,
&ctx->memory);
if (ctx->memory) {
ctx->api->ReleaseMemoryInfo(ctx->memory);
ctx->memory = NULL;
}
}
void release_ort_ctx(ort_ctx_t *ctx) {
if (!ctx) return;
struct {
const char *name;
OrtStatus *(*fn)(ort_ctx_t *ctx, ort_ctx_action_t action);
} steps[] = {
{.name = "memory", .fn = ort_mem_helper},
{.name = "allocator", .fn = ort_act_helper},
{.name = "session", .fn = ort_ses_helper},
{.name = "environment", .fn = ort_env_helper},
};
for (size_t i = 0; i < sizeof(steps) / sizeof(steps[0]); i++)
steps[i].fn(ctx, RELEASE);
ctx->model_path = NULL;
}
bool init_ort_ctx(ort_ctx_t *ctx, const char *model_path) {
bool res = false;
OrtStatus *status = NULL;
ctx->model_path = model_path;
ctx->api = OrtGetApiBase()->GetApi(ORT_API_VERSION);
struct {
const char *name;
OrtStatus *(*fn)(ort_ctx_t *ctx, ort_ctx_action_t action);
} steps[] = {
{.name = "environment", .fn = ort_env_helper},
{.name = "session", .fn = ort_ses_helper},
{.name = "allocator", .fn = ort_act_helper},
{.name = "memory", .fn = ort_mem_helper},
};
// clang-format off
for (size_t i = 0; i < sizeof(steps) / sizeof(steps[0]); i++) {
status = steps[i].fn(ctx, DO_INIT);
if (status) {
fprintf(
stderr,
"[ERROR] init %s failed: %s\n", steps[i].name,
ctx->api->GetErrorMessage(status)
);
ctx->api->ReleaseStatus(status);
goto done;
}
}
// clang-format on
res = true;
done:
if (!res) release_ort_ctx(ctx);
return res;
}
// clang-format off
/**
*
* 酒精精度 苹果酸 灰分 灰分碱度 镁 总酚 类黄酮 非类黄酮酚类 原花青素 色泽强度 色调 稀释液光密度比值 脯氨酸 类别
* 0 14.34 1.68 2.70 25.0 98.0 2.80 1.31 0.53 2.70 13.00 0.57 1.96 660.0 2
* 1 12.53 5.51 2.64 25.0 96.0 1.79 0.60 0.63 1.10 5.00 0.82 1.69 515.0 2
* 2 12.37 1.07 2.10 18.5 88.0 3.52 3.75 0.24 1.95 4.50 1.04 2.77 660.0 1
*
*/
// clang-format on
int main() {
ort_ctx_t ctx = {0};
if (!init_ort_ctx(&ctx, ORT_MODEL_PATH)) {
fprintf(stderr, "Failed to initialize onnx runtime\n");
return -1;
}
// clang-format off
const char *ip_names[] = {"float_input"};
const char *op_names[] = {"label", "probabilities"};
float sample[13] = {14.34, 1.68, 2.70, 25.0, 98.0, 2.80, 1.31, 0.53, 2.70, 13.00, 0.57, 1.96, 660.0};
int64_t shape[2] = {1, 13};
OrtValue* tensor = NULL;
OrtValue *output[2] = {NULL, NULL};
int64_t *label = NULL;
float *probabilities = NULL;
OrtStatus *status = ctx.api->CreateTensorWithDataAsOrtValue(
ctx.memory,
sample, sizeof(sample),
shape, 2,
ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT,
&tensor
);
if (status) {
fprintf(
stderr,
"Failed to create tensor: %s\n",
ctx.api->GetErrorMessage(status)
);
goto done;
}
status = ctx.api->Run(
ctx.session,
NULL,
ip_names, (const OrtValue *const *)&tensor, 1,
op_names, 2, (OrtValue **)&output
);
if (status) {
fprintf(stderr, "Failed to run: %s\n", ctx.api->GetErrorMessage(status));
goto done;
}
// clang-format on
ctx.api->GetTensorMutableData(output[0], (void **)&label);
ctx.api->GetTensorMutableData(output[1], (void **)&probabilities);
printf("预测类别 = %ld\n", *label);
printf("预测概率[%ld] = %f\n", *label, probabilities[*label]);
done:
SAFE_RELEASE_VAL(ctx, tensor);
SAFE_RELEASE_VAL(ctx, output[0]);
SAFE_RELEASE_VAL(ctx, output[1]);
if (status) ctx.api->ReleaseStatus(status);
release_ort_ctx(&ctx);
return 0;
}