算法学习-决策树算法
机器学习中,决策树是一个预测模型。决策树描述对象属性(特征)与对象之间的映射关系。对未知数据的预测问题,可以简单由一些列的树的遍历操作完成。决策树的每个叶子节点都代表一类预测对象,一系列的关于特征判断的单元组成树的中间节点。决策树计算复杂度低,输出结果易于理解,对中间数据缺失不敏感,但容易过拟合。
0.数据集
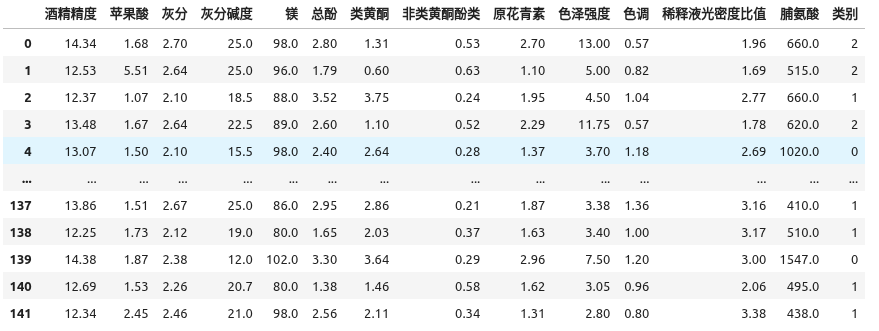
使用sklearn.datasets中的饮用酒数据集学习决策树算法,该数据集包含178个样本数据, 数据包含13个特征维度,数据被分类至3个类别。同时使用80%的样本作为训练集,剩余样本作为验证集,评价模型效果。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
from IPython.display import display
wine_features_zh = [
"酒精精度", "苹果酸", "灰分", "灰分碱度", "镁",
"总酚", "类黄酮", "非类黄酮酚类", "原花青素", "色泽强度",
"色调", "稀释液光密度比值", "脯氨酸"
]
def show_wines_data(x,y):
display(
pd.concat(
[pd.DataFrame(x, columns=wine_features_zh), pd.DataFrame(y, columns=["类别"])],
axis=1
)
)
def main():
wines = load_wine()
X_train, X_test, Y_train, Y_test = train_test_split(wines.data, wines.target, test_size=0.2, random_state=42)
show_wines_data(X_train, Y_train)
if __name__ == "__main__":
plt.rcParams["axes.unicode_minus"] = False
main()
1.决策树原理
如何构建决策树模型首先需要回答三个问题:
- 数据的那些特征维度参与模型的决策
- 这些参与决策的特征的先后顺序如何确定
- 特征的分割点的选取问题,灰分指标超过多少2.5?,应当分类至类别1,否则分类至类别2
分支创建的伪代码:
检测数据集合中的每一个数据是否都属于同一个分类:
if yes so return 分类标签
else
寻找划分当前数据集合的最优特征
划分数据集
创建分支节点
for 每一个划分的子集
调用分支创建的伪代码,并增加返回结果到分支节点中
return 分支节点
1.1基于信息熵的决策树算法
id3算法,C4.5算法(id3算法的改进版)
信息熵
在热力学系统中,熵用来衡量孤立系统的无序程度或混乱程度。同样在决策树中引入熵的概念,衡量样本的不确定性,即某个节点中各个样本分别属于不同类别的混乱程度。数学定义如下:
$$ S = -\sum_{i=1}^{m} p_i \log_2 p_i $$
- $p_i$类别: $i$在集合$S$中的比例
- 熵越高,表示数据越杂乱
决策树算法的机器学习过程,本质上就是“用特征划分训练集,不断降低信息熵”的过程。
信息增益
在一次决策中,如何评价选择哪个特征划分当前剩余样本,对整个学习过程最有利(梯度下降最大),这时需要引入信息增益这个评价指标。下面数学公式表示选取特征A作为分类条件的信息增益:
$$ Gain(S, A) = Entropy(S) - \sum_{v \in Values(A)} \frac{|S_v|}{|S|} Entropy(S_v) $$
- $S_v$,表示特征$A$取值$v$的子集
- 选择信息增益最大的特征作为节点
递归构建决策树
- 如果子集纯度为1(熵=0) → 叶子节点,标记类别
- 否则继续对剩余特征计算信息增益
- 遇到特征用完 → 用多数类别作为叶子
以上是id3算法(Iterative Dichotomiser 3)的核心思想,每次迭代都是最信息增益的局部最优求解。本质是关于信息增益的贪心算法。
1.2基于基尼指数的决策树算法
CART算法
基尼指数
在一个决策树节点中,假设有$K$个类别,第i类样本比例为$p_i$(即该类样本数/节点总样本数),基尼指数或称作Gini impurity定义为:
$$ Gini = 1 - \sum_{i=1}^{K} p_i^2 $$
可以理解为,从节点中随机抽两个样本,它们属于不同类别的概率。
基尼增益
假设使用特性$X$作为划分特征,$s$是特征的划分点,则划分后的加权基尼,数学表述如下:
$$ Gini_{\text{split}}(X, s) = \frac{N_L}{N} Gini(D_L) + \frac{N_R}{N} Gini(D_R) $$
与信息增益相似,实际是在待分类样本中,求解使得加权基尼最小时的,特征$X$及其划分点$s$,数学表示:
$$ (\hat{X}, \hat{s}) = \arg \min_{X, s} \text{Gini}_{\text{split}}(X, s) $$
递归构建决策树
决策树的构建过程也与id3算法类似,这里不再赘述。
1.3基于卡方检验CHAID算法(待补充)
CART,改进版本QUEST
2.实验演示
# pylint: disable=no-member
# pylint: disable=missing-module-docstring
# pylint: disable=consider-using-f-string
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree, export_graphviz
import pandas as pd
from IPython.display import display
import graphviz
wine_features_zh = [
"酒精精度",
"苹果酸",
"灰分",
"灰分碱度",
"镁",
"总酚",
"类黄酮",
"非类黄酮酚类",
"原花青素",
"色泽强度",
"色调",
"稀释液光密度比值",
"脯氨酸",
]
def show_wines_data(x, y):
"""
显示葡萄酒数据
"""
display(
pd.concat(
[
pd.DataFrame(x, columns=wine_features_zh),
pd.DataFrame(y, columns=["类别"]),
],
axis=1,
)
)
def main():
"""
入口函数
"""
wines = load_wine()
x_train, x_test, y_train, y_test = train_test_split(
wines.data, wines.target, test_size=0.2, random_state=42
)
clf = DecisionTreeClassifier(criterion="entropy")
clf.fit(x_train, y_train)
# sklearn统一约定:
# 所有学习到的参数、模型系数、特征重要性等都会带_,只有在调用fit函数后才会被赋值
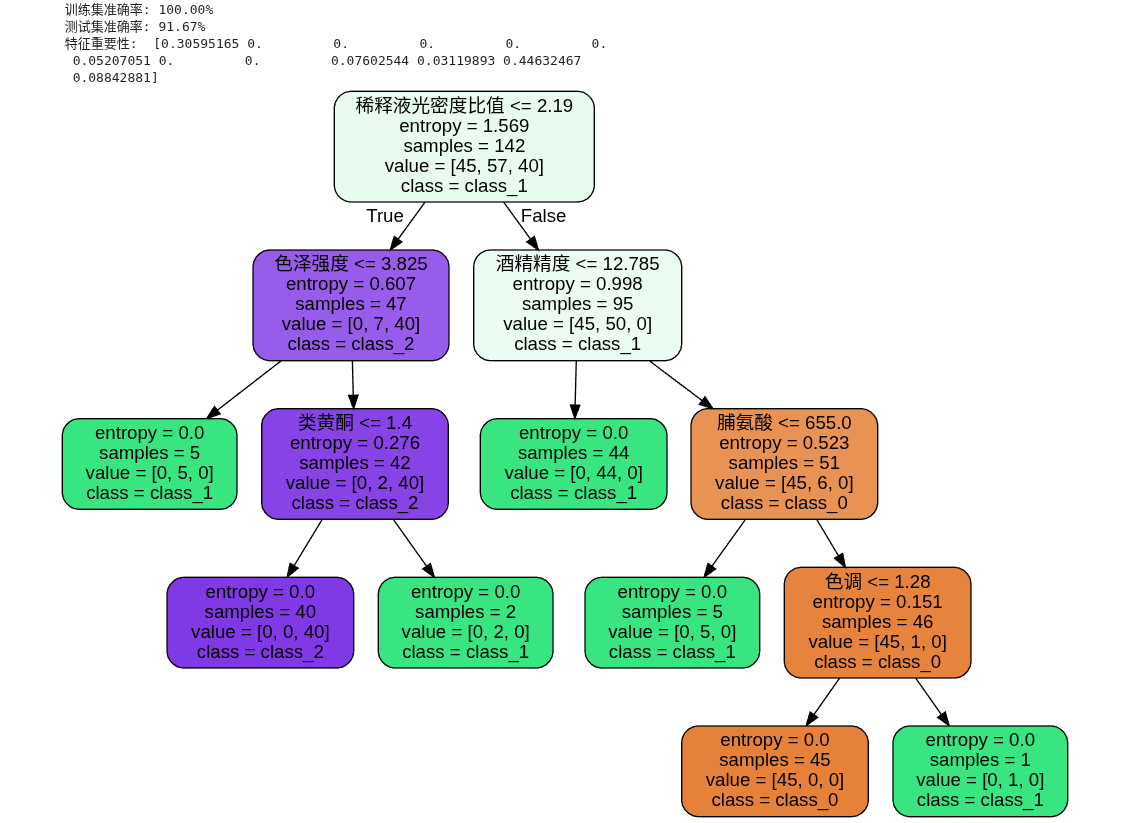
print("训练集准确率: {:.2f}%".format(clf.score(x_train, y_train) * 100))
print("测试集准确率: {:.2f}%".format(clf.score(x_test, y_test) * 100))
print("特征重要性: ", clf.feature_importances_)
dots = export_graphviz(
clf,
out_file=None,
feature_names=wine_features_zh,
class_names=wines.target_names,
filled=True,
rounded=True,
)
graph = graphviz.Source(dots)
display(graph)
if __name__ == "__main__":
plt.rcParams["axes.unicode_minus"] = False
main()